
Поисковые системы делают все возможное, чтобы индексировать страницы с высоким содержанием уникального контента. Дублированный контент может встречаться, как в рамках одного домена, так и на разных сайтах.
Задача оптимизатора помочь поисковым роботам выбрать канонический URL для показа в результатах поиска и не допустить появления новых дублей страниц.
Проблемы дублированного контента
Поисковые алгоритмы научились более точно определять оригинал от копии по множеству признаков. Вот список факторов из-за которых страницы вашего сайта могут быть признаны дублями или малополезными:
Тонкий контент — страницы с малым количеством информации. В качестве примера можно привести каталоги организаций: на сайте размещен листинг состоящий из 10 000 организаций в Москве.
При переходе в карточку организации пользователь может узнать только скромный объем данных: адрес, телефон и почтовый ящик компании.
Нарезка контента — одна из самых популярных проблем при продвижении интернет-магазинов. Уникальная карточка товара содержит одну модель товара в разных расцветках. При выборе цвета пользователь выполняет переход на другой URL.
С точки зрения поисковых систем, если у магазина есть отдельная страница для всех цветов и размеров товара, то разница между этими страницами будет незначительной.
Фрагменты — это небольшие фрагменты текста, которые могут встречаться на множестве страниц сайта (например, цитаты или дисклеймеры).
Фрагменты больше не являются большой проблемой для поисковых роботов и с легкостью разпознаются даже на страницах с большим объемом текста.
Шинглы — поисковые системы могут определять сходство между страницами найденными в интернете по пяти-шести словам. Если документы имеют много общих шинглов, один из них может быть признан дубликатом.
Сходство с популярным сайтом — сайты или их отдельные страницы, которые внешне схожи с популярным ресурсом, но не имеют схожего функционала или контента, могут быть признаны вводящими в заблуждение.
Совсем недавно в Яндексе был разработан алгоритм отбора таких сайтов для понижения их в результатах поиска.
Что такое дубли страниц?
Дубли — это страницы сайта с одинаковым или идентичным содержанием. Их наличие на сайте может оказывать негативное влияние на взаимодействие сайта с поисковыми системами.
Как правило, дублированный контент в рамках одного домена не является вредоносным и представляет собой:
- Страницы с GET-параметрами,
- Страницы товаров, доступные по разным URL,
- Страницы с шаблонным текстом,
- Версии страниц для печати.
Если вы используете идентичный контент для обмана пользователей, ваш сайт будет частично или полностью ограничен в результатах поиска.
Проверка дублей страниц на сайте
Чтобы проверить наличие дублей страниц — добавьте сайт в Яндекс Вебмастер и обратитесь к разделу Индексирование -> Заголовки и описания. Здесь показаны все URL с одинаковым текстовым содержанием в тегах <title> и <description>:
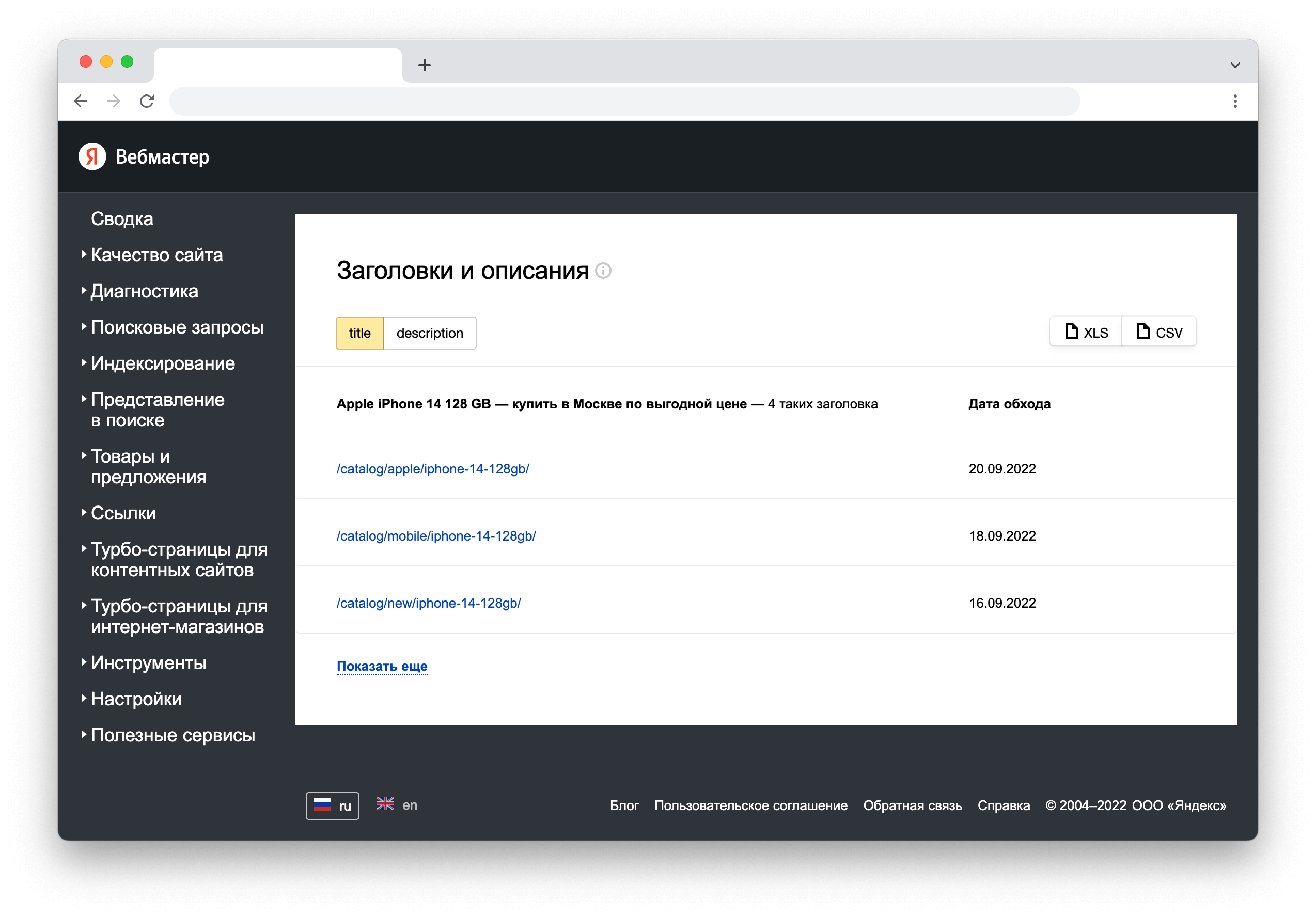
В разделе Индексирование -> Страницы в поиске можно найти страницы, которые были исключены из поиска по причине наличия дубликатов. Для удобства работы, задайте фильтр, как показано на рисунке, и скачайте таблицу с результатами сканирования:
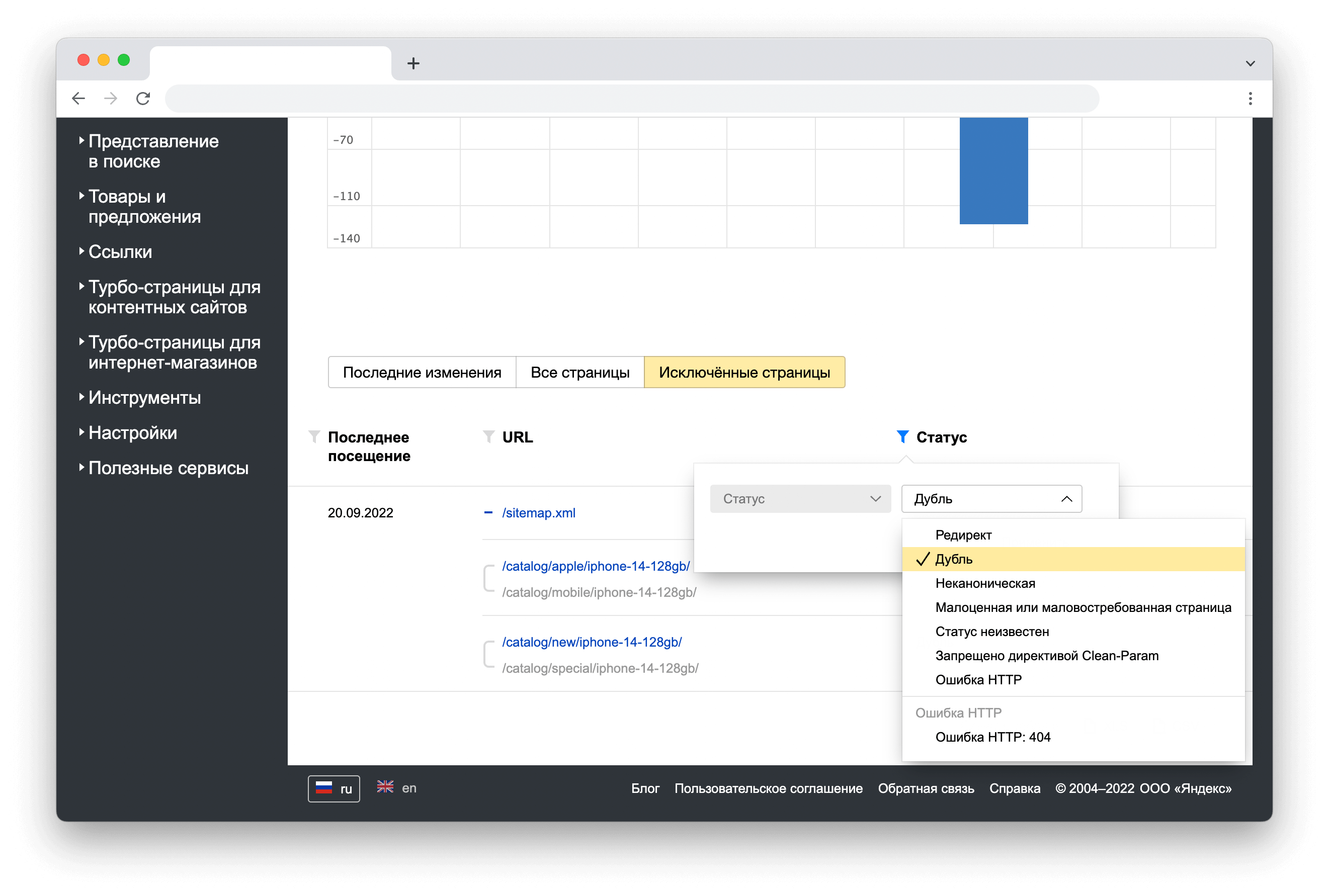
Удаление дублей страниц
Оптимизатору доступны несколько способов удаления дублей страниц из поиска. В таблице представлены основные методы борьбы с дублями. Их можно применять, как отдельно друг от друга, так и вместе в рамках одного проекта.
| Метод | Описание |
|---|---|
| 301-редирект | Полезен в случаях, когда принято решение о полном прекращении показа копии страницы в поиске. Настраивается в CMS с помощью плагинов или в конфигурации сервера. |
HTML-тег rel="canonical" | Основной инструмент для борьбы с дублями. Тег с указанием канонического URL должен быть размещен в исходном коде страницы в секции <head>. |
| HTTP-заголовок | В отличие от HTML-страниц к файлам нельзя применить другие методы указания канонического адреса, кроме заголовка ответа. Используется для нормализации документов в различных форматах. |
| Clean-param | Директива для удаления копий страниц с GET-параметрами. Поддерживается только в поиске Яндекса. |
Метатег noindex | Не рекомендуется для отклонения дублей. Тег должен быть размещен в исходном коде страницы в секции <head>. |
| Файл Robots | Позволяет закрыть от сканирования копии страниц с помощью директивы Disallow. Использование метода не рекомендуется для поисковой системы Google. |
| Файл Sitemap | Метод избыточен, так как роботу требуется повторная проверка URL указанных в карте сайта. Для роботов Google этот сигнал является менее значимым, чем атрибут canonical. |
Для чего нужно выбирать канонический URL
Удаление дублей позволяет кратно ускорить индексирование сайта поисковыми системами и увеличить количество переходов за счет его лучшего ранжирования в результатах поиска.
Установка канонических URL
К сожалению, разработчики систем управления контентом не уделяют большого внимания проблеме дублированного контента. Во многих CMS не предусмотрена быстрая настройка 301 редиректов и канонических страниц.
«1С-Битрикс»
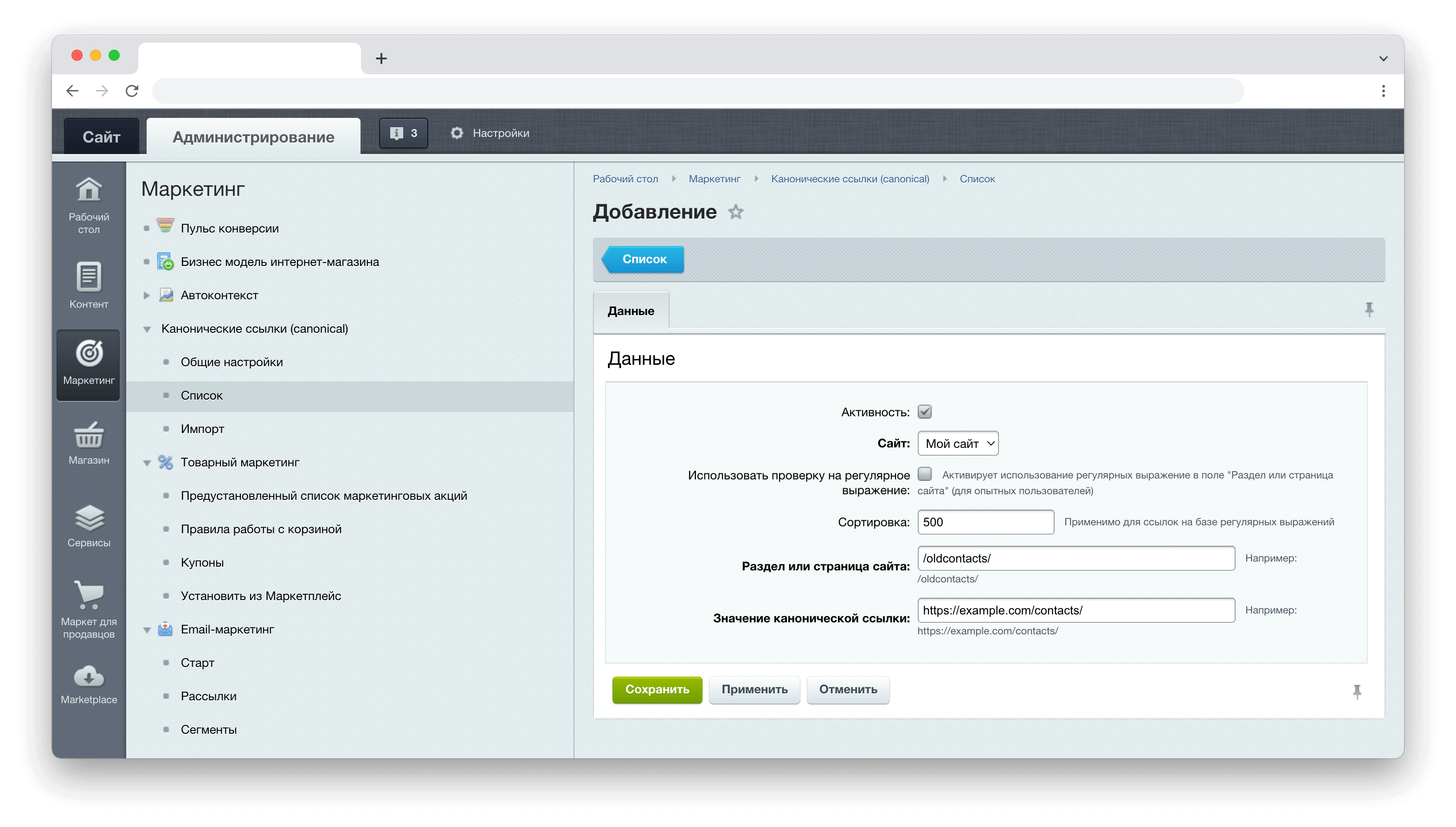
В качестве примера, укажем канонический адрес на сайте под управлением «1С-Битрикс». Этот модуль позволяет добавить каноническую ссылку на страницу через панель администрирования.
Чтобы задать канонический URL с помощью тега rel="canonical" в исходном коде страницы, достаточно заполнить поля, как показано на рисунке. Укажем поисковому роботу, какой из двух URL является первоисточником:
WordPress
Для сайтов под управлением WordPress так же доступно несколько бесплатных плагинов для работы с каноническими адресами.
Вы можете установить любой SEO-плагин из репозитория или внедрить функционал самостоятельно. В ядре WordPress имеется стандартная функция для вывода канонических URL в исходном коде — rel_canonical().